一、为什么需要强大的本地知识库?
通用 LLM 训练于公开数据,它知道什么是「年假」,但不知道你们公司年假是 5 天还是 15 天。它知道「润滑脂」是工业润滑剂,但不知道你们仓库里用的是 NLGI 2 号还是 3 号。
这就是 RAG(检索增强生成)要解决的问题——在 AI 回答问题之前,先让它到你的私有知识库里翻一遍资料,翻到了再回答。
先搞清需求层级:你属于哪种?
在 OpenClaw 生态里,知识管理其实有多个层次,适用于不同场景:
| 方案 | 适合场景 | 重量级 | 最大文档量 |
|---|---|---|---|
| OpenClaw MEMORY.md | 个人日常:聊天记录、偏好、简短备忘 | 🟢 极轻 | 几十条 |
| Obsidian 等本地知识库 | 个人笔记、项目管理、写作素材 | 🟡 较轻 | 几百篇 |
| RAGFlow 专业 RAG 引擎 🎯 | 专业学者、小型/大型团队:行业报告、技术文档、制度手册、图纸说明等数千份材料 | 🔴 较重(约 8-16GB 内存) | 数千份稳定可靠 |
三种方案不是替代关系,而是互补。MEMORY.md 管日常对话记忆,Obsidian 管个人笔记,而本文要讲的 RAGFlow 解决的是「海量文档级知识库」——你的文档不是几十篇笔记,而是几百上千份 PDF、制度文件、技术手册、行业报告,需要一个专业引擎来管理。
为什么一定要本地部署?
| 对比 | 本地知识库 | 云知识库服务 |
|---|---|---|
| 隐私安全 | ✅ 全部数据在自己电脑上 | ❌ 公司制度、技术文档要上传别人服务器 |
| 断网可用 | ✅ 局域网内随时随地 | ❌ 没网就废了 |
| 长期成本 | ✅ 一次性硬件投入 | ❌ 按存储+调用量持续收费 |
| 数据主权 | ✅ 随时删、随时改、自己说了算 | ❌ 受平台条款约束 |
对于数千份文档规模的场景,云服务不仅贵,数据安全也是大问题。本地部署是唯一合理的方案。
目前最成熟的开源方案组合,就是 RAGFlow + OpenClaw。
二、正常安装 RAGFlow 的流程(简短表述)
安装 RAGFlow 本身不算难,但步骤多且杂。如果你从零开始手动部署,大概要做这些事:
1. 环境准备
→ 开启 BIOS 虚拟化(VT-x/AMD-V,大部分电脑默认已开,可跳过)
→ 管理员 PowerShell 运行 wsl --install,自动安装 WSL2 和 Ubuntu
→ 重启电脑
2. 安装 Docker Desktop
→ 去官网下载安装
→ Settings → Resources → WSL Integration 确认 Ubuntu 已启用
→ 启动 Docker,等待右下角鲸鱼图标亮起
3. 部署 RAGFlow 容器
→ git clone 仓库 → cd docker → docker compose up -d
→ 等 5-10 分钟下载镜像和初始化
4. 登录 RAGFlow Web 界面
→ 浏览器打开 http://localhost:9222
→ 注册管理员账号
5. 生成 API Key
→ 在 Web 界面里点「设置」→「API Keys」→ 创建新 Key
→ 复制出来保存好
6. 配置模型
→ Embedding 模型(向量化)
→ Chat 模型(对话)
→ Rerank 模型(重排序)
→ 每个都要手动添加和激活
7. 创建知识库、上传文档、启动解析
→ 在 Web 界面操作,一步步点
8. 拿到 API Key 后,再配置到 OpenClaw 技能里
→ 安装官方 Skill → 配置 .env → 才能开始用
全部做完,快的话 20 分钟,慢的话一个小时起步。中间还可能遇到各种报错——端口冲突、镜像拉取失败、容器启动失败、嵌入模型配置报错……每一个都够新手卡半天。
而且这些步骤没有任何一个是可以跳过的。缺了任何一步,OpenClaw 都没法和 RAGFlow 连上。
三、嫌麻烦的话,可以用 ragflow-workbench 技能
Openclaw如此强大,为什么不让Openclaw帮我安装?
因此我把上述所有手动步骤让Openclaw帮我一步步执行完成,并封装成一个 OpenClaw 技能——ragflow-workbench
1. 安装技能
此skill我已经上传到SkillHub中,可以复制此文本让Openclaw自己安装:
请先检查是否已安装 SkillHub 商店,若未安装,请根据 https://skillhub.cn/install/skillhub.md 安装Skillhub商店,但是只安装CLI,然后安装ragflow-workbench技能。
若已安装,则直接安装ragflow-workbench技能。
安装后,在 OpenClaw 配置中启用该技能,你就可以直接在聊天框里和它对话了。
2. 当你在 OpenClaw 里说「我想加个知识库」时
不再需要你去看教程、翻文档、记 API。OpenClaw 会主动和你对话:
你: 我想给我的 AI 加一个本地知识库
OpenClaw: ❓ 您是否还没有下载安装 RAGFlow?需要我帮您下载安装吗?
或者您已经部署了 RAGFlow?请告诉我地址和账号密码(或 API Key),
我帮您自动测试连接。
然后根据你的回答,走对应的路径:
路径 A:全新安装(你选「帮我装一个」)
OpenClaw 一步步引导你:
**「先检查一下虚拟化是否开启(大部分电脑默认已开,不用纠结)。」
**「然后用管理员身份打开 PowerShell,运行 wsl --install 安装 WSL 和 Ubuntu。」
**「装好后去 https://www.docker.com/products/docker-desktop/ 下载安装 Docker Desktop。」「启动 Docker Desktop,在 Settings → Resources → WSL Integration 里确认 Ubuntu 已启用。」
「一切就绪后,在终端执行:」git clone https://github.com/infiniflow/ragflow.git cd ragflow/docker docker compose up -d「等 5-10 分钟让 RAGFlow 初始化,好了告诉我,我来检查环境。」
你告诉它「好了」,剩下的事情脚本自动完成:
▶ scripts/check_windows_install.py
自动检查:Docker 运行 ✅ 容器启动 ✅ API 端口通 ✅ Web 端口通 ✅
▶ scripts/bootstrap_admin.py
容器内加密密码 → 注册管理员 → 登录获取 Token → 创建 API Key
→ 自动写入 .env 文件 ✅ (你不需要碰 Web 界面)
▶ scripts/configure_default_models.py
自动配置 Embedding 模型(bge-m3)
自动配置 Chat 模型(qwen2-7b-instruct)
自动配置 Rerank 模型(bge-reranker-v2-m3) ✅
OpenClaw: ✅ 全部就绪!现在你可以上传文档到知识库了。
配置RagFlow模型:技能支持自动配置牧马人 Herdsman 推理引擎中的本地模型
装好 RAGFlow 之后还需要配模型才能用——Embedding 模型负责把文档转成向量,Chat 模型负责回答问题,Rerank 模型负责优化检索排序。
正常情况下你得去 RAGFlow Web 界面一个个手动添加模型供应商、输入 API 地址、测试连接。但如果用云端模型还要额外申请 API Key 和付费,对小白来说又是一道坎。
ragflow-workbench 的解决办法:技能内置了自动调用牧马人 Herdsman 模型推理引擎的本地模型进行配置,自动调用本机提供的本地模型算力。
牧马人 Herdsman 是一个本地模型推理引擎,支持在普通电脑上运行 Embedding、Chat、Rerank 模型,无需 GPU、无需联网、无需申请云 API。详情与下载安装链接:FlowyAIPC-牧马人本地推理引擎
安装引导完成后,脚本会自动执行:
▶ scripts/configure_default_models.py
自动启动 Herdsman 本地推理引擎
配置 Embedding 模型(bge-m3)——向量化你的文档
配置 Chat 模型(qwen2-7b-instruct)——回答你的问题
配置 Rerank 模型(bge-reranker-v2-m3)——优化检索排序
全部对接本地 Herdsman 服务,不依赖任何云端 API ✅
这意味着什么?
- ✅ 不用去申请 OpenAI / DeepSeek / 通义千问的 API Key
- ✅ 不用配置外部模型供应商地址
- ✅ 所有模型跑在本机,不联网也能用
- ✅ 不产生任何 API 调用费用
如果你自己已经部署了其他模型服务(比如 Ollama、vLLM),也可以在配置时指定地址:
uv run python scripts/configure_default_models.py ^
--api-base http://host.docker.internal:8080/v1 ^
--chat-model deepseek-chat ^
--json
路径 B:已有 RAGFlow,给地址和密码
你: 我已经部署了,地址 192.168.1.100,账号 admin@xxx.com,密码 xxxx
脚本自动测试连接 → 登录 → 创建 API Key → 写入 .env。
不用自己去 Web 界面翻设置页。
路径 C:已经有 API Key
你: 这是我的 API Key:xxxxxxxx
直接测试有效性 → 有效就写入 .env → 跳过所有引导步骤。
一次搞定,以后不用再管
.env 写入后,后续所有 OpenClaw 会话自动跳过引导流程。不会每次都被问「你要不要装 RAGFlow」。
之后就是正常使用了。
五、日常怎么用:用白话指挥你的知识库
装好之后,你和 OpenClaw 的对话不再只是聊天——你的每一句指令都可能牵动知识库的增删改查。来看看最常见的几种场景:
场景 1:单文件入库
你: 帮我把这份员工手册 PDF 添加到知识库
OpenClaw: 收到,正在上传 C:\文档\员工手册.pdf 到知识库「公司制度」……
OpenClaw: ✅ 上传完成(1.2MB),正在解析,预计 10 秒后可用。
(来源:员工手册.pdf · 正在解析中,进度 42%)
你想加任何一个文件,直接告诉 OpenClaw 文件路径和放哪个知识库就行。不需要打开 RAGFlow 的 Web 界面。
场景 2:批量文件夹入库
你: 把这个「行业报告」文件夹里所有 PDF 都上传到知识库
OpenClaw: 正在扫描 C:\行业报告\ 目录,找到 23 个 PDF 文件……
OpenClaw: 创建新知识库「行业报告」→ 批量上传中(共 23 个文件)……
OpenClaw: ✅ 23 个文件全部上传完成,正在排队解析,完成后我会通知您。
OpenClaw(10 分钟后): 解析完成,23/23 成功。知识库「行业报告」现可查询。
不用一个个手动操作。文件夹拖进去,剩下的 OpenClaw 处理。
场景 3:基于知识库回答问题
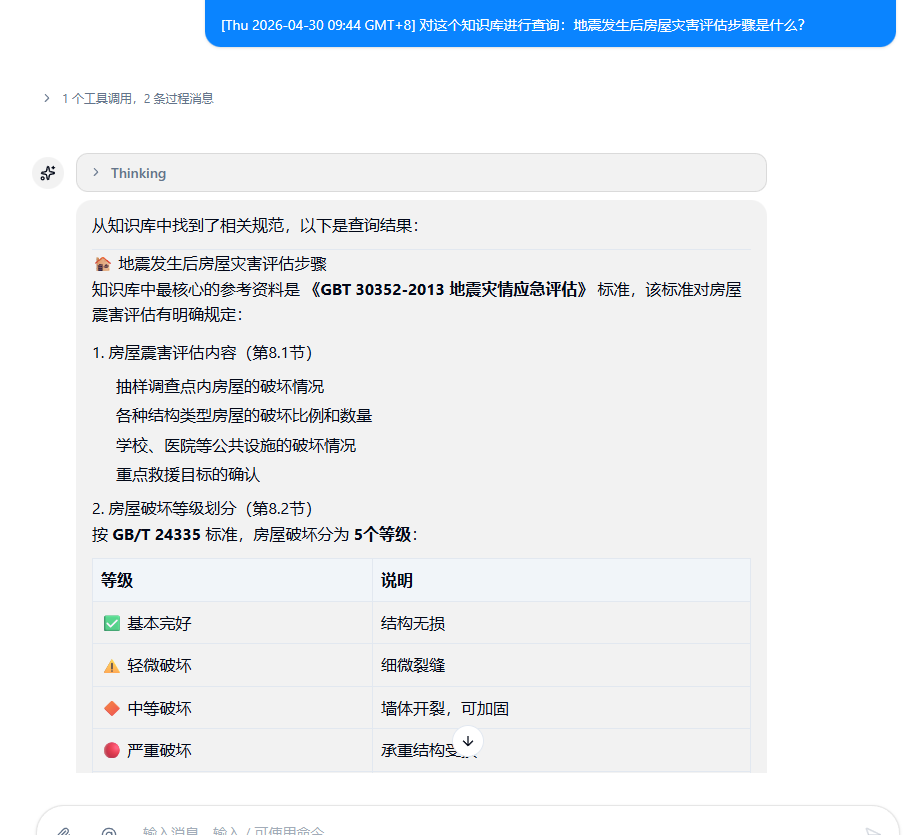
这是最核心的日常场景。你问的问题,AI 会自动去知识库里检索,找到相关文档片段,基于这些片段回答:
你: 入职满一年年假几天?
AI: 根据《员工手册》第四章第2条,入职满一年享5天年假。
(来源:员工手册.pdf · 第12页)
你: 我们公司调休怎么规定的?
AI: 调休只适用于休息日加班,工作日和法定节假日不予调休。
(来源:考勤制度.docx · 第8条)
你: 对比前两年的行业报告,说说市场趋势变化
AI: 检索到 2024 和 2025 年行业报告共 6 篇,关键趋势变化如下:
1. 2024年重点在 A(来源:2024行业报告.pdf)
2. 2025年转向 B(来源:2025行业趋势分析.docx)
每个回答都标注了引用来源,你可以追溯到原文。
场景 4:基于知识库整理信息、撰写文章
RAGFlow 不止能回答具体问题——你还可以让它基于知识库的内容,帮你归纳、提炼、成文:
你: 把知识库里关于「高温润滑脂」的所有资料整理成一篇技术说明文
AI: 我在知识库中检索到 12 篇相关文档,涵盖产品规格书、技术手册和质检报告。以下是整理后的技术说明:
—(正文)—
本文基于以下参考资料撰写:
• 润滑脂选型指南(第3章 · 高温应用)
• NLGI 分级标准说明书
• 2025 年高温润滑脂质检报告
你: 汇总一下知识库里所有和「安全生产」有关的条款,分 risk level 整理成表格
AI: 已检索到 5 份相关制度文件,共提取 21 条安全生产条款:
| risk level | 条款数 | 主要来源 |
|------------|--------|----------|
| 🔴 高危 | 3 | 安全生产管理制度.pdf |
| 🟡 中危 | 8 | 同上 + 应急预案.docx |
| 🟢 低危 | 10 | 员工安全手册.pdf |
如果是写报告、做培训材料、整理信息汇总的场景,直接让 OpenClaw 基于知识库帮你写,结果有据可查。
场景 5:跨知识库查询与综合
如果你的知识库按主题分得很细(比如「公司制度」「产品资料」「行业报告」),可以同时查多个:
你: 查一下我们公司的产品在行业标准中的定位
AI: 已检索知识库「产品资料」(8 篇)和「行业报告」(5 篇),发现:
• 产品 A 符合 GB/T XXXX 标准(来源:产品规格书.pdf)
• 行业最新标准在 2025 年已更新至 YYYY 版本(来源:行业报告_2025.docx)
• 建议升级产品 B 以符合新版标准(来源:技术评审会议纪要.pdf)
以上所有操作,全程只需要你在 OpenClaw 聊天框里说一句话。 不用打开 RAGFlow Web 界面,不用查 API 文档,不用写代码。