
牧马人本地推理引擎 API 玩法指南
核心目标:通过 Python 代理 + 专用 HTML 界面,利用牧马人本地推理引擎部署的本地模型实现“文本对话生成分镜脚本 → 批量生图 → 导出素材”的自动化工作流。
一、硬件配置建议
| 显存大小 | 可用模式 |
|---|---|
| 4GB ≤ 显存 < 8GB | 仅对话模式,目前可能无法使用生图生图模型 |
| 8GB ≤ 显存 < 12GB≥ | 对话 + 生图需分步启动(先关对话再开生图) |
| ≥ 12GB | 可同时启动对话模型与生图模型 |
提示:本方案推荐配置 4B 对话模型,显存占用低,适合大多数本地设备。
二、前置准备
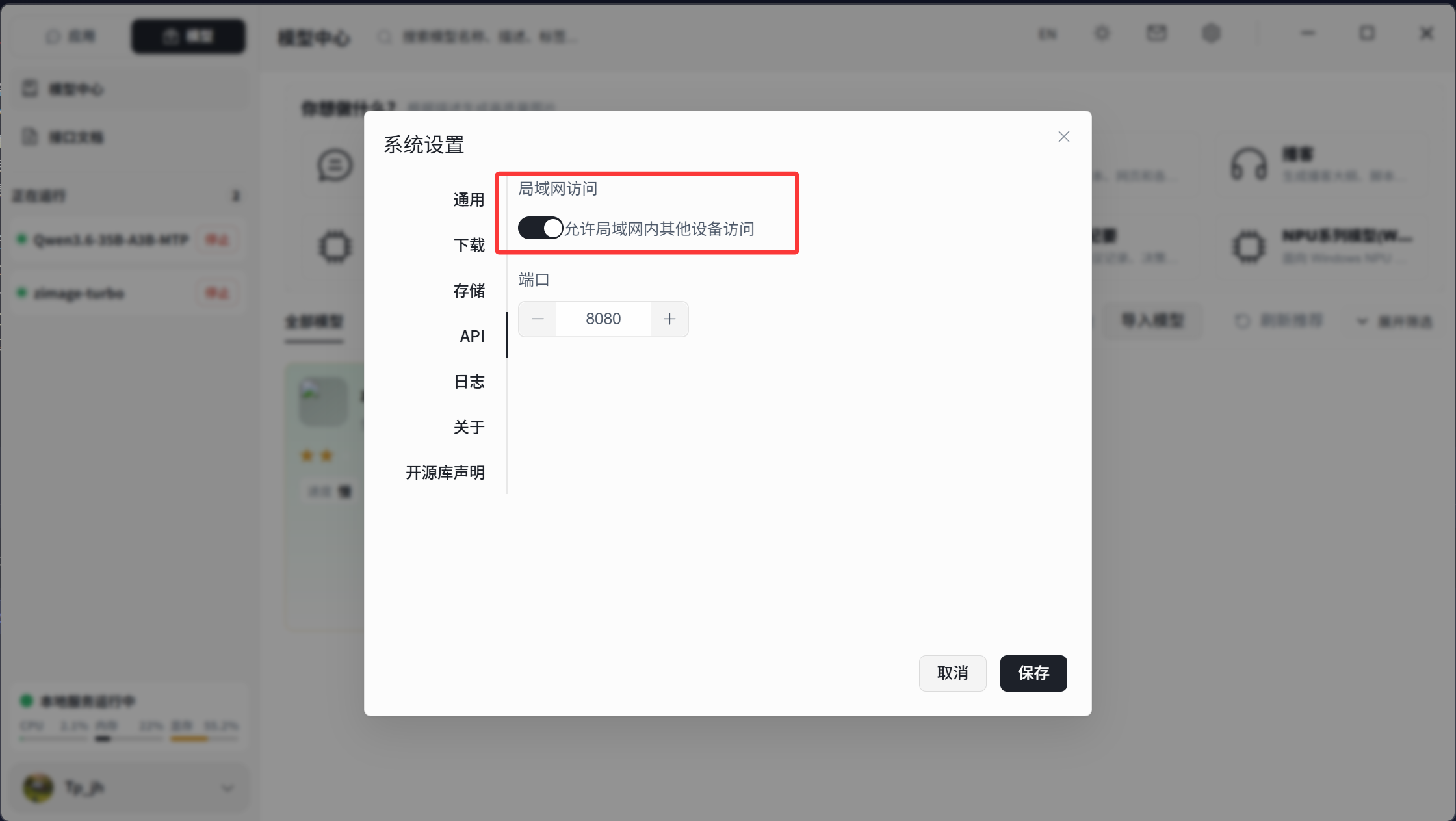
1. 开启局域网访问权限
· 打开 Herdsman 设置
· 进入 右上角系统设置 → API
· 勾选 允许局域网访问
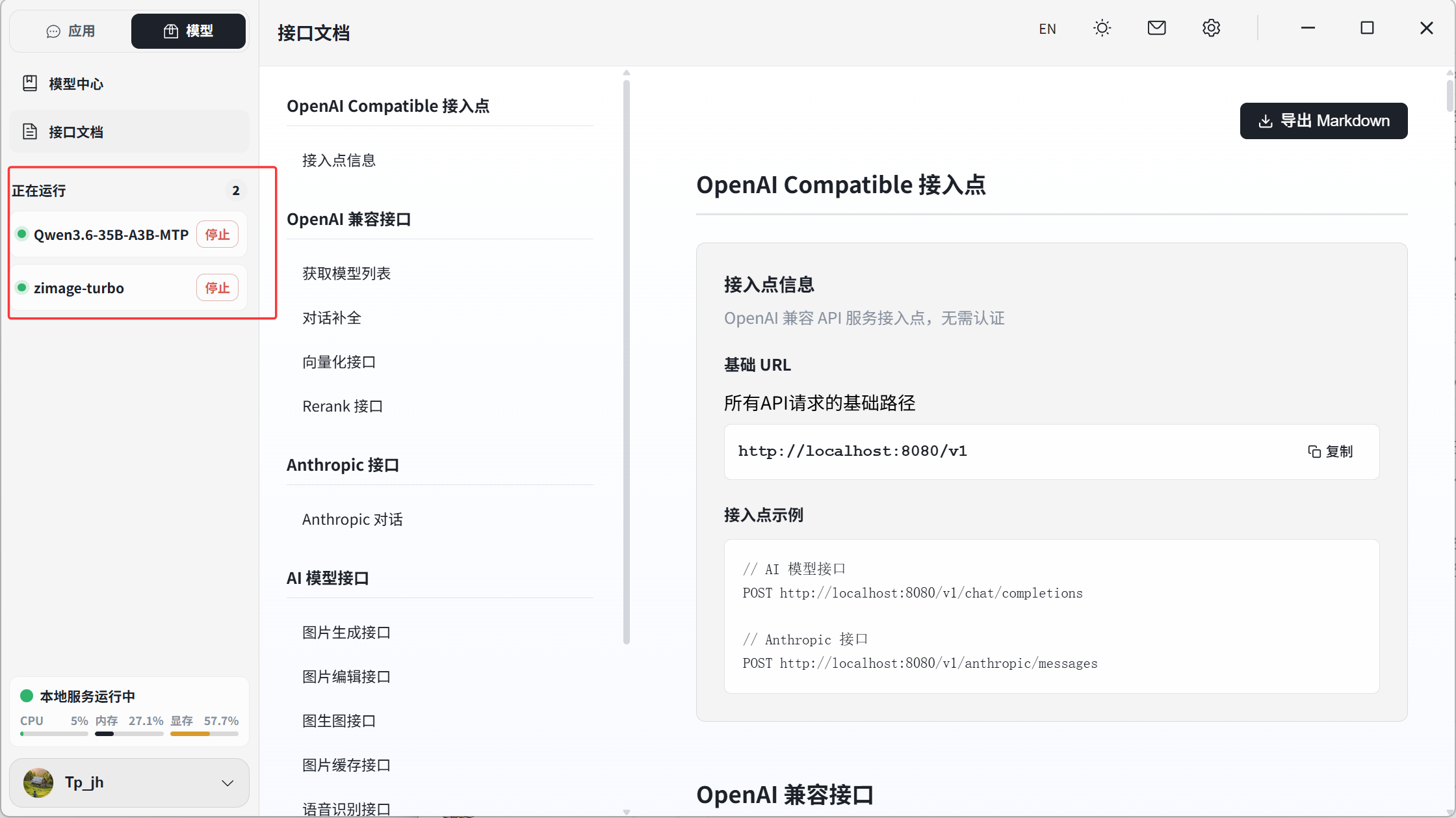
2. 启动对话模型
在模型管理界面启动 对话模型以及生图模型(如 Qwen3-4B-Instruct和z-imge 等)
接下来会用到的python文件和html文件点击此链接进行获取:https://wwaxs.lanzoub.com/iOgHw3qhrd7e
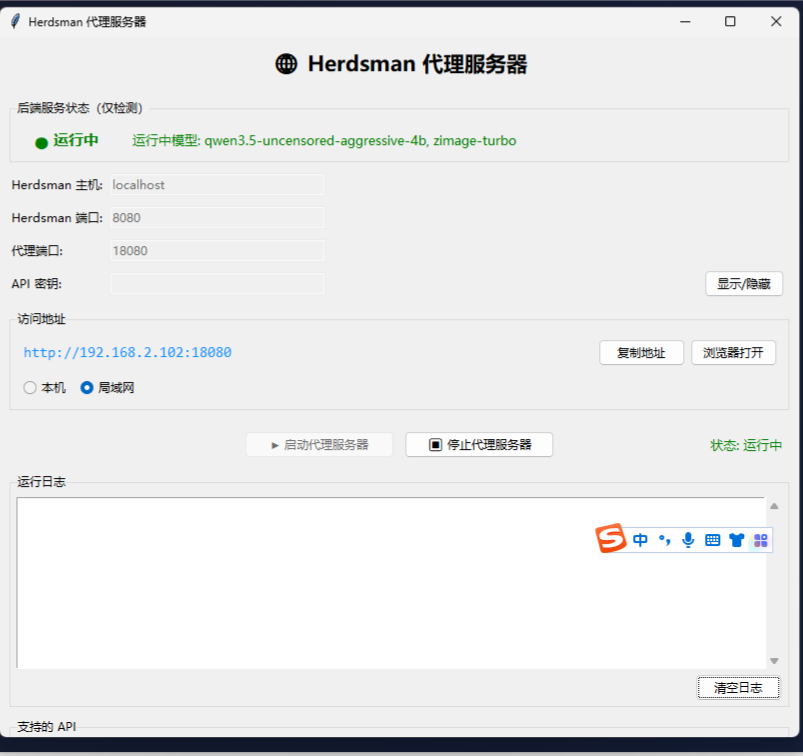
3. 启动本地代理服务器
运行脚本:herdsman_server_gui.py(如果你不会运行py脚本,只需打开FlowyAIPC,告诉FlowyAIPC脚本地址,并让它启动即可)默认端口:127.0.0.1:8080
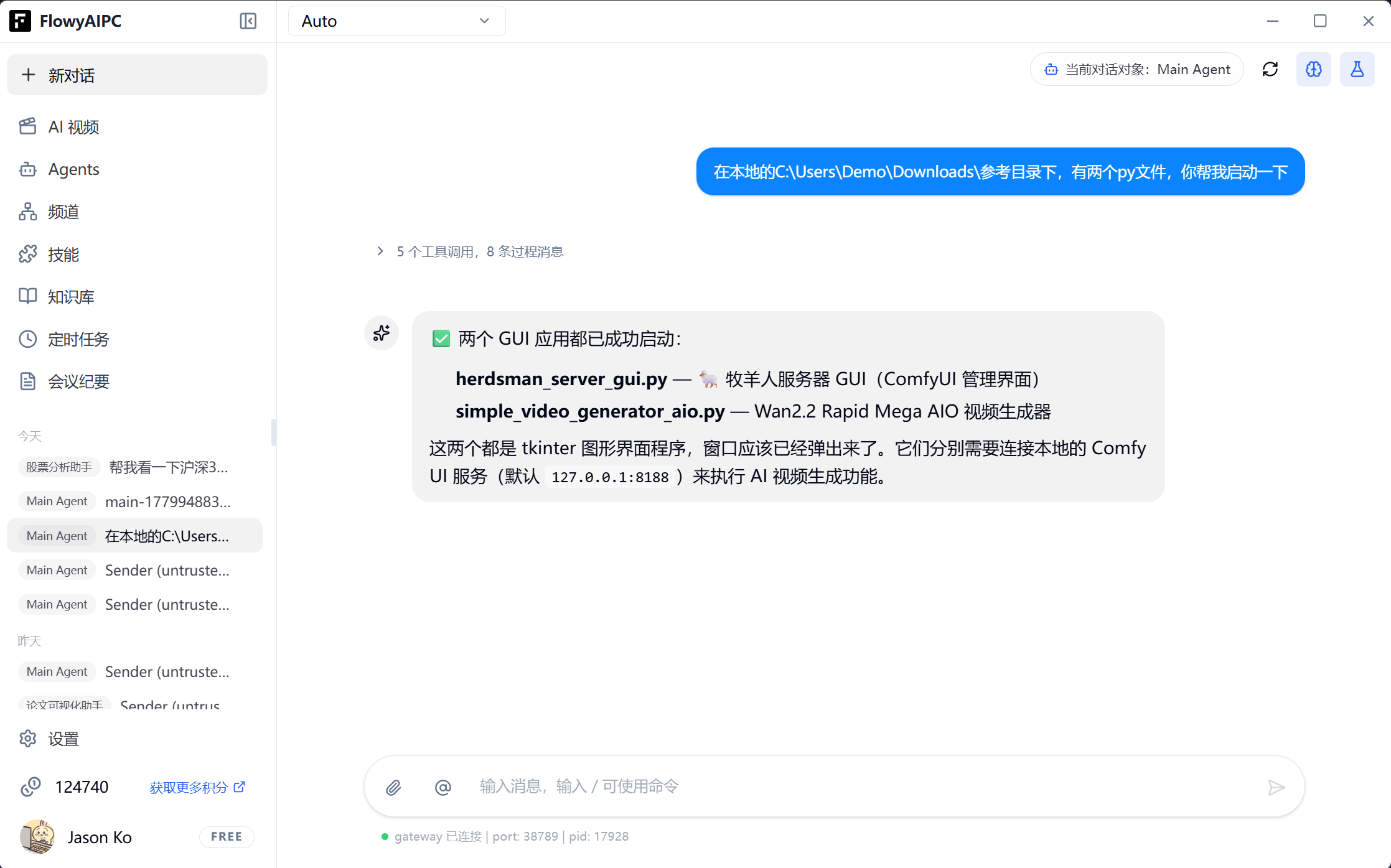
打开herdsman代理服务器的GUI界面以后,点击“启动代理服务器”,代理类型选择:
o 仅本地使用 → 选“本机”
o 手机/局域网使用 → 选“局域网”(关键!)
三、使用专用 HTML 界面
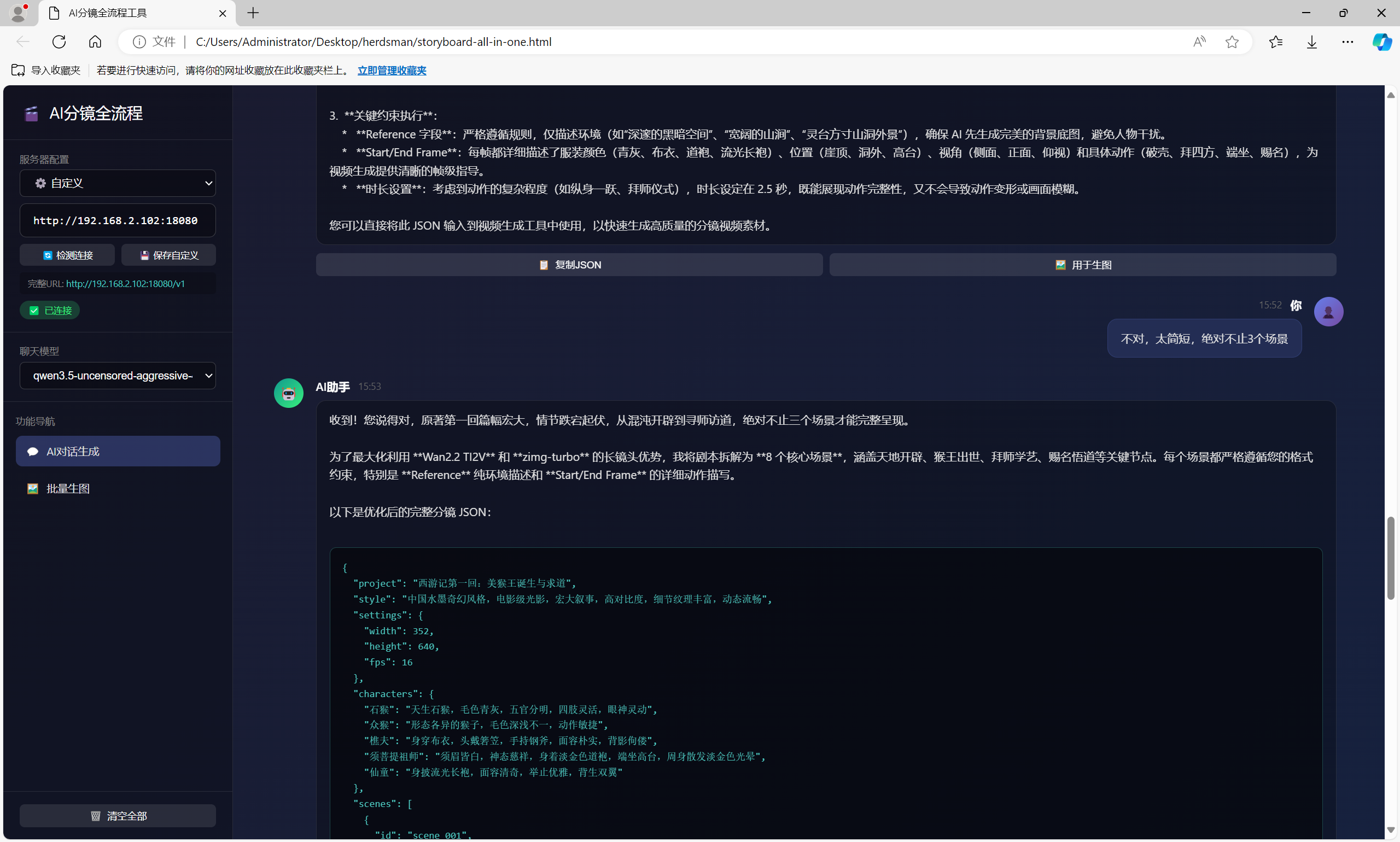
1. 打开 HTML 文件
双击打开
storyboard-all-in-one.html,进入 左上角“自定义网址”
粘贴代理服务器地址(如 http://127.0.0.1:8080)
点击 测试链接 确认连通性

注意:局域网其他设备链接模型则把127.0.0.1替换为运行模型设备的实际地址即可,地址获取方式如下:
快捷键win+R打开运行窗口,输入“cmd”,点击确定
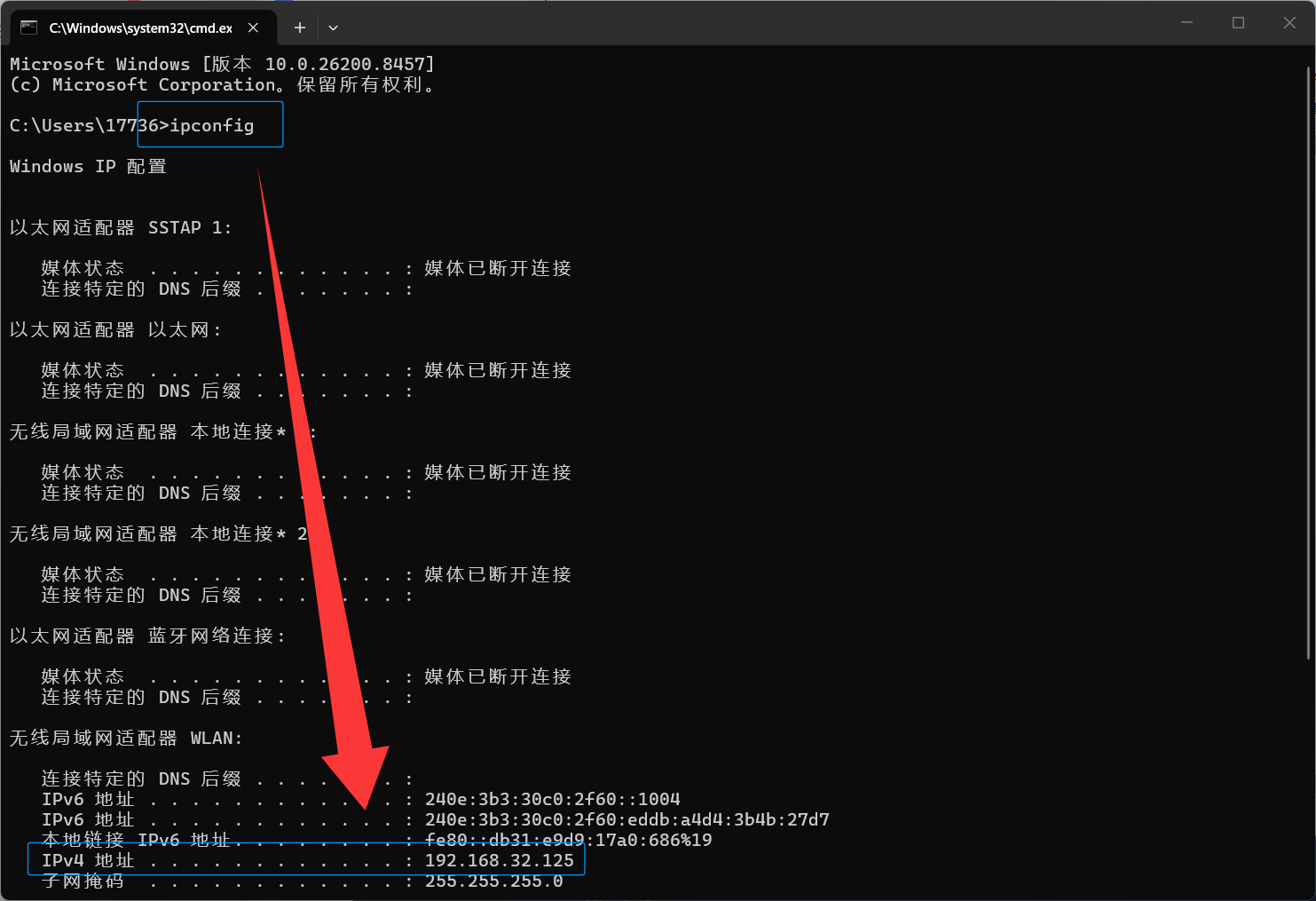
打开控制台以后,输入“ipconfig”,查看ipv4的地址,这个地址就是设备在局域网的唯一ip
2. 生成分镜脚本
在对话框中输入:
o 示例提示词:“生成武侠风格分镜脚本”或“生成霸道总裁场景”
o 文学作品输入:“西游记第一回”
若场景不足,可补充指令:“请细分更多战斗/对话场景”
系统将输出结构化 分镜 JSON 脚本(含角色、场景、动作描述)
3. 批量生图
点击 “批量生图” 按钮
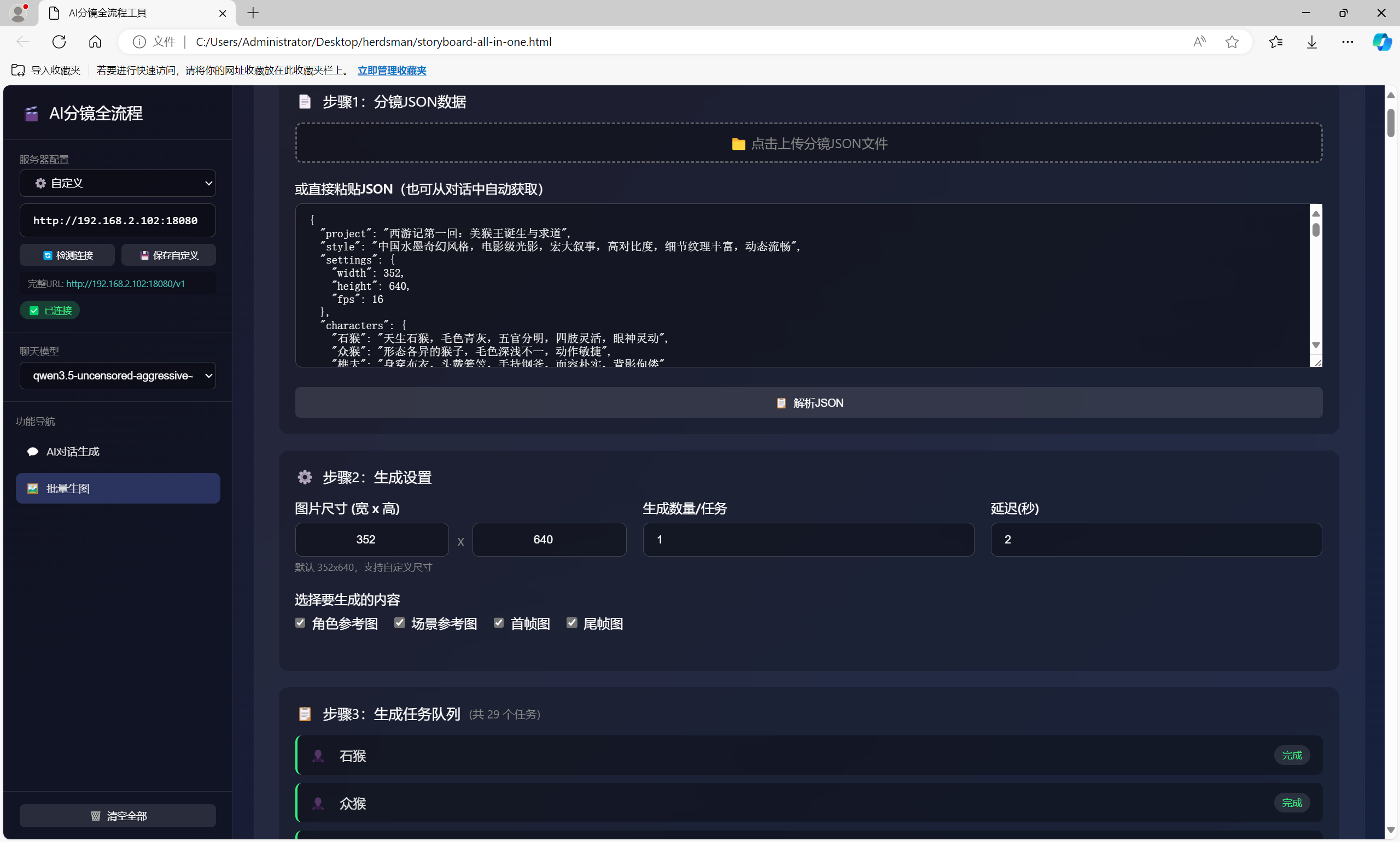
系统自动按以下逻辑生成:
1. 角色参考图
2. 场景首帧
3. 场景尾帧
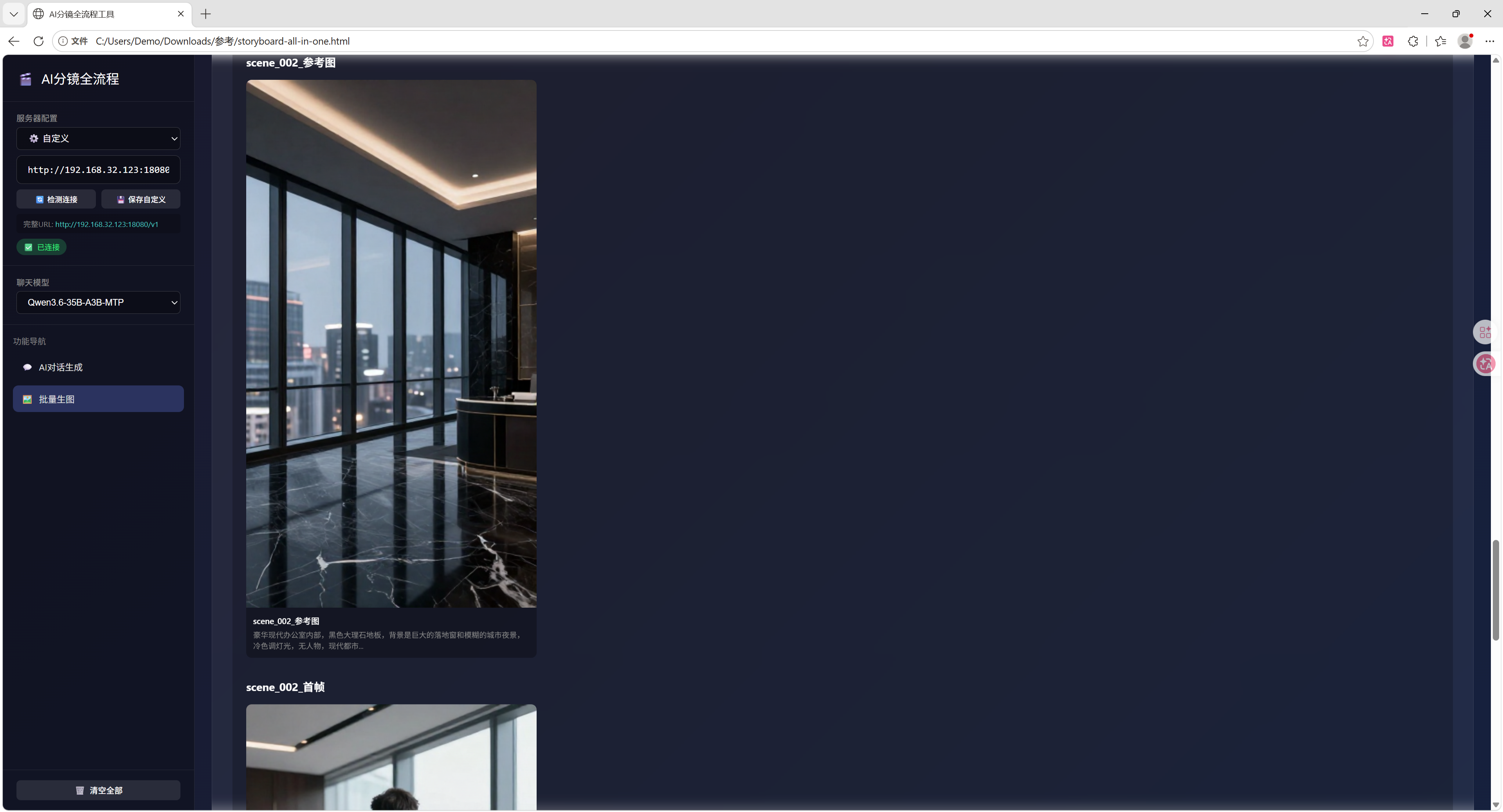
建议另存至专用目录(如
./outputs/herdsman_20260527)
生成后可用于:
- ComfyUI Wan2.2AIO 工作流
- 后续视频首尾帧生成(可直接在FlowyAIPC的AI视频创作进行生成)
四、手机端使用流程
1. 确保代理选“局域网”
2. 将
storyboard-all-in-one.html 通过以下方式传输至手机:
- USB 转 OTG
- 微信/QQ 文件传输
- 局域网共享
3. 使用 MT 管理器 或 ES 文件浏览器 将文件移至固定目录(如
/storage/emulated/0/Download/herdsman/)
4. 用浏览器打开并 收藏主页,方便快速访问
5. 操作逻辑与电脑端一致
五、工作流程总结
graph TD
A[开启局域网 API] --> B[启动 4B 对话模型]
B --> C[运行 herdsman_server_gui.py]
C --> D[启动局域网代理]
D --> E[打开 HTML 并配置代理地址]
E --> F[输入文本生成分镜 JSON]
F --> G[批量生图:角色/首帧/尾帧]
G --> H[保存至自定义目录]
H --> I[供 ComfyUI/Wan2.2 使用]
六、进阶建议
· 脚本优化:在分镜生成后,可添加“细化动作”、“增加特效”等指令优化脚本。
· 视频生成:待系统支持首尾帧视频生成后,可在此工作流中直接输出视频片段。
· 多设备协作:通过局域网代理,可在多台设备间共享生成结果。
核心价值:将文本创意转化为视觉素材的完整本地闭环,无需依赖云端,保护隐私且零延迟。
非常感谢社区用户@狼牙 分享的教程
